
CFP: Making Sense of Metrics: Crafting and Leveraging Prometheus Metrics for Infrastructure Intelligence
February 29, 2024 9:28 amAudience
This talk is targeted at System Administrators and Site Reliability Engineers interested in learning about how to best make sense of the Prometheus metrics their system exposes. If you know PromQL, but the queries behind your dashboards are still a mystery to you, you are not alone. This talk will show how to get information out of your metrics to maximize the insights and make data-based decisions.
Outline
Creating new metrics and collecting them with Prometheus is easier today than it was ever before. Site Reliability Engineers and System Administrators have all the data at hand they need to make the right, data-based decisions. But how?
Making sense of all that information is still a challenge. Crafting the right PromQL query to answer your question and manifesting it in a Grafana dashboard is a complex and time-consuming task. Not speaking of understanding that query when you need to change it a few weeks later.
In this session, you will see different approaches to make sense of the prometheus metrics exposed by a software deployment: Starting from the default Prometheus UI, via PromLens, an improved, open source query-building UI, all the way to an experiment on transforming Prometheus metrics into a data warehouse for improved data exploration and visualization. Data analysts have used Business intelligence software for decades. What can we learn from these systems to discover knowledge in the ocean of metrics to make better decisions for our infrastructure?
Key Takeaways
During this talk, attendees should have learned how to (1) best explore and query the available metrics in their environment, (2) which tools are available today and (3) how infrastructure intelligence can leverage data warehouse concepts for improved knowledge discovery and decision making.

Pod Autoscaling in OpenShift and Kubernetes
November 24, 2022 11:05 amTo test out the horizontal pod autoscaling I built a simple example application that shares “load” across instances. The load is as simple as allocating a configurable chunk of memory.
When the load increases, the pod autoscaler would spin up new instances so the chunks get smaller and the target is reached.
You can find the example application on Github.
Run locally
Check out the repository, run make build and start ./pod-autoscaler-example.
It will allocate the default 100MiB of RAM and wait for additional instances to connect:
$ ./pod-autoscaler-example
Can't connect to main instance at localhost:8081, assuming there is none and acting as mainWaiting for server to be responding...
Instance ID: main
Allocating 100 Mi
Instance ID: main Variable size: 100 Mi Allocated: 100 Mi
Instance ID: main Variable size: 100 Mi Allocated: 100 Mi
Instance ID: main Variable size: 100 Mi Allocated: 100 Mi
Starting a second instance will share the “load” across instances:
$ ./pod-autoscaler-example
Instance ID: nXii9k5RhdcdwYcBKw6hRT
Can't run worker server, assuming we run on one host: listen tcp :8081: bind: address already in useAllocating 50 Mi
Instance ID: nXii9k5RhdcdwYcBKw6hRT Variable size: 50 Mi Allocated: 50 Mi
Instance ID: nXii9k5RhdcdwYcBKw6hRT Variable size: 50 Mi Allocated: 50 Mi
Instance ID: nXii9k5RhdcdwYcBKw6hRT Variable size: 50 Mi Allocated: 50 Mi
Instance ID: nXii9k5RhdcdwYcBKw6hRT Variable size: 50 Mi Allocated: 50 Mi
Increase the workload (this is what should trigger the autoscaler later) using curl:
$ curl localhost:8081/set?mem=300
All instances should get the new workload size now:
Allocating 150 Mi
Instance ID: nXii9k5RhdcdwYcBKw6hRT Variable size: 150 Mi Allocated: 150 Mi
Instance ID: nXii9k5RhdcdwYcBKw6hRT Variable size: 150 Mi Allocated: 150 Mi
Instance ID: nXii9k5RhdcdwYcBKw6hRT Variable size: 150 Mi Allocated: 150 Mi
Stopping the main instance will result in a re-election workflow (not too suffisticated, yet, but it should keep the workload size):
Error sending request to getInstanceInfo: Get "http://192.168.178.46:8082/getInstanceInfo": dial tcp 192.168.178.46:8082: connect: connection refused
Assuming main is not responding anymore. Checking who can take over.
New main: nXii9k5RhdcdwYcBKw6hRT My ID: nXii9k5RhdcdwYcBKw6hRT
Taking over...
Waiting for server to be responding...
Instance ID: main
Allocating 300 Mi
Instance ID: main Variable size: 300 Mi Allocated: 300 Mi
Instance ID: main Variable size: 300 Mi Allocated: 300 Mi
Since there are only two instances left, the workload per instance is increased.
A metrics endpoint is available so you can observe the application using prometheus:
$ curl localhost:8081/metrics
instances_count 2
workload_mib 300
chunksize_mib 150
Running on OpenShift/Kubernetes
Resources in the deploy folder can be used to run it on a Kubernetes or OpenShift cluster.
The deployment in deploy.yaml will create a single instance, the service and route (svc.yaml and route.yaml) are used to expose it. Note that the command passes the service hostname and port to the containers so they can initiate communication when new instances come up.
The horizontal pod autoscaler in hpa.yaml will increase and decrease instances as necessary when the load increases/decreases.
Using the route, you can scale the workload with curl as shown above:
$ curl pod-autoscaler-example-autoscaler-example.apps.mycluster.com/set?mem=200
The servicemonitor in servicemonitor.yaml makes the metrics available for Prometheus. When using OpenShift, you can query them in the OpenShift console:
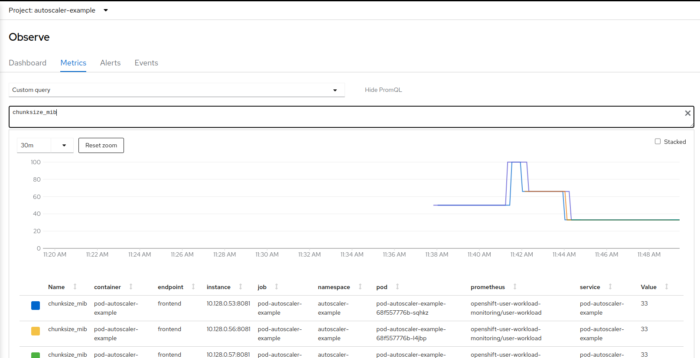
you can see how the chunk size first went up when the workload was increased, and then back down when the autoscaler kicked in and scaled the deployment.

Kubernetes: Distributing Pods of a Deployment across nodes
May 17, 2022 9:14 amSometimes you need to ensure that the pods of a deployment are not deployed to the same node. To achieve this, you can use the pod anti-affinity and configure it so that pods do not get deployed to pods of the same deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: game
name: game
namespace: arcade
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
app: game
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: game
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- game
topologyKey: kubernetes.io/hostname
containers:
- image: quay.io/mdewald/s3e
name: s3eThis pod anti-affinity definition will not deploy any 2 pods of the deployment onto the same node.
During the roll-out, additional pods are created before old pods are removed. If you have the same number of nodes as replicas, that means the roll-out won’t happen: No node is available to suffice the criteria to deploy an additional pod. So in the best case, you should have more nodes available than the deployment requires replicas.
You can work around this problem by changing from requiredDuringSchedulingIgnoredDuringExecution to preferredDuringScheduilingIgnoredDuringExecution:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- game
topologyKey: kubernetes.io/hostname
weight: 100However, this would allow some of the pods of the deployment to land on the same node during a roll-out of the deployment. After the roll-out, they will be distributed one pod per node again.
If you absolutely don’t want to ever have 2 pods of the same deployment run on the same node but don’t have more nodes than replicas, it can be an option for you to migrate from a Deployment to StatefulSet, which will first terminate each pod before creating a new one:
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: game
name: game
namespace: arcade
spec:
replicas: 2
selector:
matchLabels:
app: game
serviceName: ""
template:
metadata:
creationTimestamp: null
labels:
app: game
spec:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- game
topologyKey: kubernetes.io/hostname
containers:
- image: quay.io/mdewald/s3e
name: s3eThis will ensure no pod of the StatefulSet is scheduled to the same node. If you have the same number of nodes as replicas in the StatefulSet the rollout will do the following: One by one, the pods will be removed and the replacement will be scheduled to the same node before the next pod is removed.

CFP: Up your Game with OpenShift
October 21, 2021 9:18 amAutomatic build and deployment for your very own browser game
Audience
This talk is targeted at anybody using or planning to use OpenShift to deploy their software. It’s not exactly for game developers, but probably for people who want to learn what it can mean to build a game with Open Source software and deploy it to an OpenShift cluster so it can be accessed via a web browser, or people who want to know about the possibilities to automate software build and deployment with OpenShift.
Outline
OpenShift comes with various built-in tools that can help developers bring their own software to the cloud – or their cluster.
From automatic builds based on dockerfiles via source-to-image (S2I) builds to a full-blown pipeline with Tekton, a solution is there for all use-cases one can think of. All use-cases? How about the small browser-game developer around the corner?
In this talk we’ll explore the possibilities to provide a custom S2I image for very specific use-cases, like building and running a game built with the Godot engine. We will use the image to trigger automatic builds and deployments of a small browser game whenever a change is published to the games’ GitHub repository.
Key Takeaways
During this talk the audience will see (1) the different possibilities OpenShift provides to automate and customize a build process, (2) how to build a custom builder image for S2I builds, and (3) get an idea of which option could be a good fit for their own projects.

CFP: The CR that goes around in circles
April 13, 2021 1:18 pmA tale of common pitfalls in operator and CRD design and how to avoid them
Audience
This talk is targeted at an audience that already made some experience or interest in designing and implementing Kubernetes operators. The terms Custom Resource Definition (CRD), Custom Resource (CR) and operator pattern should be known to them. For examples that are mentioned during the talk, it is based on the Operator SDK, however most patterns are independent of the framework in use.
Outline
When designing and implementing Kubernetes operators, we naturally need to think about CRDs and how a good CRD looks like. While operators often act on existing Kubernetes resources, in most cases we want to build our own objects, which is one of the main advantages of operators: Building and operating on custom types that seamlessly integrate into the Kubernetes control plane.
In this talk we will shed light on some common pitfalls, and share some considerations for designing new CRDs and operators. The goal is to enable everyone to build and run operators that work smoothly and avoid CRs that go around in circles.
Key Takeaways
During this talk the audience will see (1) common mistakes in operator design that lead to behaviors like CRs that never leave the reconcile loop, (2) learn how to avoid them, and discover (3) how an ideal CRD should look like that minimizes the risk of such mistakes.

Things I always search for when writing a new BASH script
November 25, 2020 8:16 amGet the directory of the script
When writing a bash script, especially when it is distributed via a git repository and depends on other files in the same repository, it is often important to know the location of the script to use relative paths to other files. Particularly, getting the directory of the current script allows users to execute the script from wherever they want and the script can still depend on files similar to using a relative path. This one-liner is what I typically do to get the location of the current script, found on Stack Overflow.
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
Building Kubernetes Operators
November 17, 2020 4:33 pmIn the past months ad Red Hat I dove a bit into operator development. During learning how to build Kubernetes operators myself I published a quick start article on opensource.com . Using Operator SDK is a good way to kick-start your own Kubernetes operator.
While the post itself is based on an older version of the SDK and usage has changed, you should be able to get such an example operator up and running quickly using this post and a later version of the Operator SDK.
While working on different operators, I wrote down patterns and best practices I learned or discovered in the different projects, which I wrote down on a blog post on openshift.com. The CFP CFP: How to build a Kubernetes operator that doesn’t break production is mainly based on this blog post. If you want to build your own Operator, those two blog posts may help you build an operator that is easy to build, maintain and run.

CFP: How to build a Kubernetes operator that doesn’t break production
September 21, 2020 8:46 amAudience
This talk is targeted at software developers and SREs interested in development practices for Kubernetes operators. Are they interested in how development of an operator is different from other software projects? This project will give an outline of the operator pattern and how development looks like, focusing on the importance of good engineering practices. Are they writing a Kubernetes operator just to automate a simple task? They should write tests for it, and this talk will tell them why. As Site Reliability Engineers in OpenShift Dedicated, we’re developing and maintaining a number of operators to keep toil on all our operated clusters as low as possible.
Outline
In a recently published blog post I wrote about how to make sure a Kubernetes operator project is maintainable and follows software development best practices. As SREs we create and maintain a growing number of Operators to keep toil away from us. But a poorly designed, implemented or tested operator can just create toil on its own by not functioning correctly. Adding new features to it can get hard for SREs as bugs can go in undiscovered and the confidence in adding new code can be low if the operator lacks an adequate test suite.
In this talk I will talk about the important concepts you should keep in mind when developing your own Kubernetes operator. Even if you want to start a new project just to automate the setup and configuration of a small application, make sure to give all the attention to good software development practices it needs, even if you feel this could slow down the development and even take you more time than just performing that task by hand. Software grows, and in the long run it will pay out if you craft a tested and readable operator from the beginning.
Key Takeaways
During this talk, attendees should have learned the importance of (1) treating a Kubernetes operator as production code. (2) It is very helpful to wrap external dependencies, where (3) tests will help achieve this goal as well as help improve the overall structure of the code.

CFP: 5 agile practices and why they are useful to SRE teams
April 21, 2020 2:28 pmAs SRE (Site Reliability Engineering) teams contain a fair portion of software development work, and get filled up by software developers, it is a natural move to also adapt agile software development practices. The right agile model depends heavily on the percentage of development work vs. operations, which may be influenced by the team size. For example, in a small team where a high percentage of people is on call during the day, it might not make too much sense to plan sprints of 2 weeks if only a few backlog items are expected to get done in that timeframe.
Audience
This talk is targeted at everyone involved in Site Reliability Engineering, wondering how much agile to adopt – team leads, product owners, software developers, SREs. If you’re planning to transform your ops team into an SRE team, your SRE team just got started, or already do SRE since quite some time. As a software engineer who recently joined SRE, I will talk about which practices I found useful to take over from software engineering, which ones are better dropped, and which ones I’m still missing sorely.
Agile Practices
Retrospective
While often being the first meeting to get dropped by teams as the relation to actual work items cannot be seen easily, the retrospective meeting is the tool for teams to iterate on how they work and improve, including which of the agile practices make sense to adopt it which don’t.
Planning: Estimating Backlog Items
Planning meetings help the team understand priorities of items, the overall direction a project is heading and get a common understanding of how complex work is (with estimation). However, given a (not known) number of people is on call or doing incident response makes it hard to set sprint goals or commit to a consistent number of stories.
Standups
Standup meetings are useful, especially in distributed teams, to talk about what you’re working on and where you need help. Frequency of the meeting does not necessarily be daily – and that hit me as software engineer unexpectedly hard.
Testing
If your SRE team is writing software, that software should be tested. No room for discussion.
That’s what the software engineer might think – but you need to discuss. You need to convince your team testing is helpful. And that’s as equally hard in an SRE team as in any software engineering team.
Pair programming
It’s hard to convince people pair programming is helpful, and it isn’t helpful in every situation – but confidence in code as well as operations changes (in an outage for example) is so much higher when working in a pair.
Key Takeaways
During this talk, attendees should have learned (1) that SRE and software engineering likewise benefit from agile development practices, of which at least (2) some practices are worth to adopt while others may not be too helpful for SRE. (3) Which ones are and are not helpful can be the easiest spotted by iterating not only work but also how we work (practice retrospectives).

Guest article: Build a Kubernetes Operator in 10 minutes with Operator SDK
April 20, 2020 1:53 pmIt’s been a while since I last submitted an article to opensource.com. This time it is about quickly kick-starting a Kubernetes Operator with Operator SDK. Click here to get to the article.
When you start working on a new software project, often a bunch of code is already existing. That’s by no means different when joining development of a Kubernetes Operator. In the case of Operator SDK a good part of the code is additionally generated, so you also want to know which code is hand-written, meant for changes, and which is generated by the SDK.
As I’ve been working on the GCP Project Operator with my team at Red Hat, I wanted to know what exactly the steps are to start an operator from scratch, to better understand what it is, that you get from the SDK. I thought it might also be useful for other hopping on operator development, so I wrote those steps down in a blog article.